
在这篇博文中,我们将介绍 Cloudbreak,Solana 的水平扩展状态架构
概述:RAM、SSD 和线程
当在不进行分片的情况下扩展区块链时,仅扩展计算是不够的。用于跟踪帐户的内存很快就会成为大小和访问速度的瓶颈。例如:人们普遍认为,许多现代链使用的本地数据库引擎 LevelDB 在单台机器上无法支持超过 5,000 TPS。这是因为虚拟机无法通过数据库抽象利用对帐户状态的并发读写访问。
一个简单的解决方案是在 RAM 中维护全局状态。然而,期望消费级机器有足够的 RAM 来存储全局状态是不合理的。下一个选择是使用 SSD。虽然 SSD 将每字节成本降低了 30 倍或更多,但它们比 RAM 慢 1000 倍。以下是最新三星 SSD 的数据表,它是市场上最快的 SSD 之一。
单笔交易需要读取 2 个账户并写入 1 个账户。账户密钥是加密公钥,完全随机,没有真实的数据局部性。用户的钱包会有很多账户地址,每个地址的位与任何其他地址完全无关。由于帐户之间不存在局部性,因此我们不可能将它们放置在内存中以使它们可能彼此接近。
每秒最多 15,000 次唯一读取,使用单个 SSD 的帐户数据库的简单单线程实现将支持每秒最多 7,500 个事务。现代 SSD 支持 32 个并发线程,因此可以支持每秒 370,000 次读取,或每秒大约 185,000 个事务。
Cloudbreak 破云
Solana 的指导设计原则是设计不妨碍硬件的软件,以实现 100% 的利用率。
组织帐户数据库以便在 32 个线程之间可以进行并发读取和写入是一项挑战。像 LevelDB 这样的普通开源数据库会导致瓶颈,因为它们没有针对区块链设置中的这一特定挑战进行优化。 Solana 不使用传统数据库来解决这些问题。相反,我们使用操作系统使用的几种机制。
首先,我们利用内存映射文件。内存映射文件是其字节被映射到进程的虚拟地址空间的文件。一旦文件被映射,它的行为就像任何其他内存一样。内核可能会将部分内存缓存在 RAM 中,或者不将其缓存在 RAM 中,但物理内存的数量受到磁盘大小的限制,而不是 RAM 的大小。读取和写入仍然明显受到磁盘性能的限制。
第二个重要的设计考虑因素是顺序操作比随机操作快得多。这不仅适用于 SSD,也适用于整个虚拟内存堆栈。 CPU 擅长预取按顺序访问的内存,而操作系统则擅长处理连续页错误。为了利用这种行为,我们将帐户数据结构大致分解如下:
账户和分叉的索引存储在 RAM 中。
帐户存储在最大 4MB 的内存映射文件中。
每个内存映射仅存储来自单个提议分叉的帐户。
地图随机分布在尽可能多的可用 SSD 上。
使用写时复制语义。
写入会附加到同一分叉的随机内存映射中。
每次写入完成后都会更新索引。
由于帐户更新是写时复制并附加到随机 SSD,因此 Solana 获得了顺序写入和跨多个 SSD 进行横向写入以进行并发事务的好处。读取仍然是随机访问,但由于任何给定的分叉状态更新都分布在许多 SSD 上,因此读取最终也会水平扩展。
Cloudbreak 还执行某种形式的垃圾收集。随着分叉在回滚之外最终确定并且帐户被更新,旧的无效帐户将被垃圾收集,并且内存将被放弃。
这种架构至少还有一个更大的好处:计算任何给定分叉的状态更新的 Merkle 根可以通过跨 SSD 水平扩展的顺序读取来完成。这种方法的缺点是失去了数据的通用性。由于这是一个自定义数据结构,具有自定义布局,因此我们无法使用通用数据库抽象来查询和操作数据。我们必须从头开始构建一切。幸运的是,现在已经完成了。
Benchmarking Cloudbreak Cloudbreak 基准测试
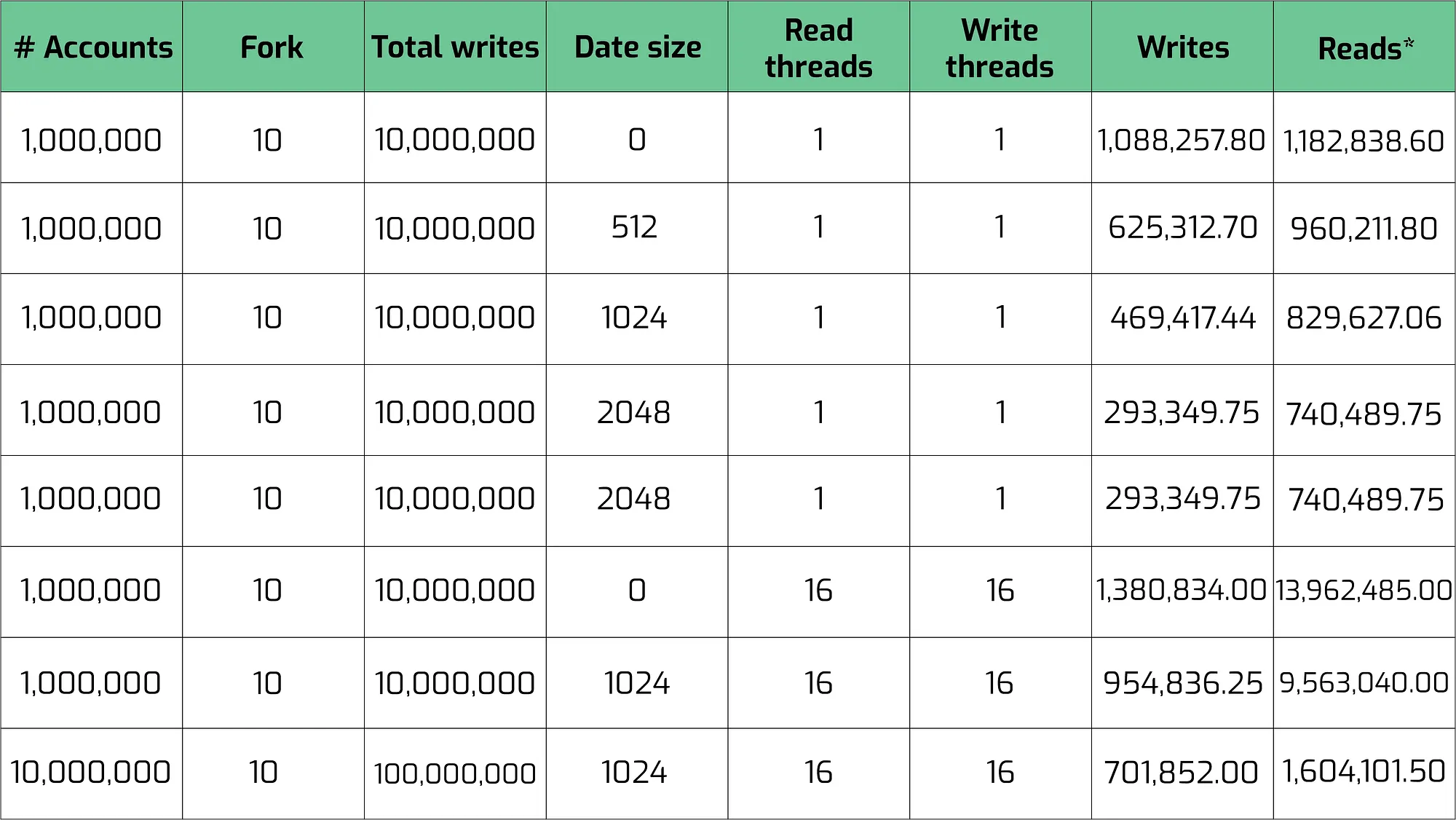
虽然帐户数据库位于 RAM 中,但我们看到吞吐量与 RAM 访问时间相匹配,同时随可用内核数量进行扩展。当帐户数量达到 1000 万时,数据库不再适合 RAM。然而,我们仍然看到单个 SSD 上每秒读取或写入的性能接近 1m。